Building your first plot: scatter plots#
Before we delve a little deeper into some of the concepts we introduced in the previous section with regards to what makes a graphic “good”, let’s lay the foundations and build our first plot. You need a draft to start improving on it!
In this session, we are going to work step-by-step through building a basic plot. The full self-contained example script is given at the end of this page.
Tip
It’s a good idea to type the example code out in your notebook as opposed to copying and pasting. This will help you get used to the syntax and will allow you to improve your skills more rapidly.
Introduction to the tools we are using#
For this course, we are going to be using a particular tool for interacting with Python called a “Notebook”. You may have heard of the Jupyter Notebook before: this is a document format that includes snippets of formatted text, embedded executable/runnable code, and the output of said code (for example, plots/figures). We are going to be using an online version of Jupyter Notebooks hosted by Google, called Google Colaboratory, so you don’t have to install anything locally on your machine; the free version provides plenty compute power for this tutorial.
|
|---|
Click “New Notebook” to create a fresh file. Alt text: gif of Google Colab’s landing page, showing the “New Notebook” button being clicked. |
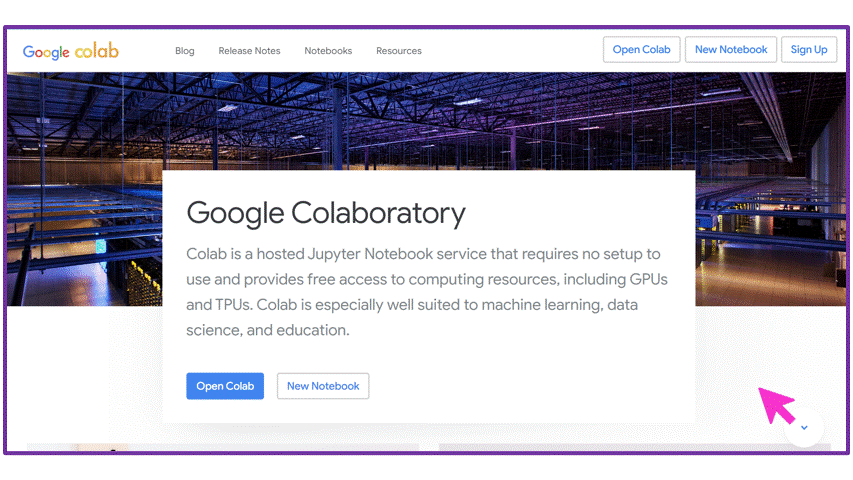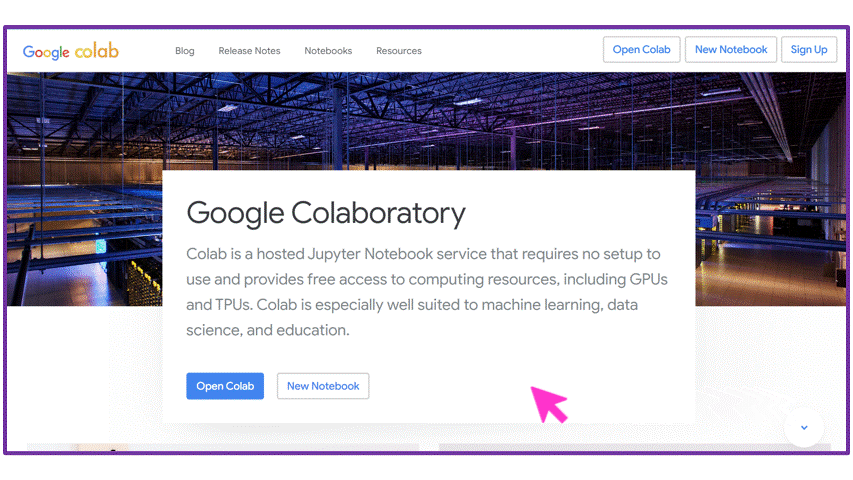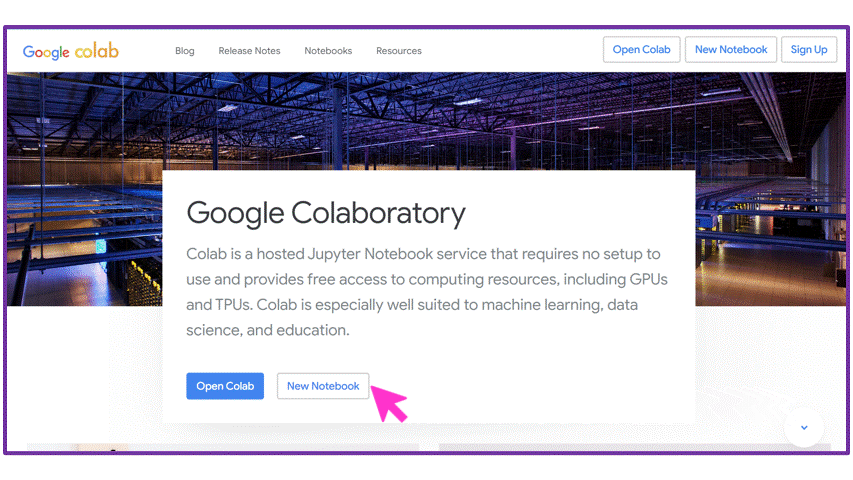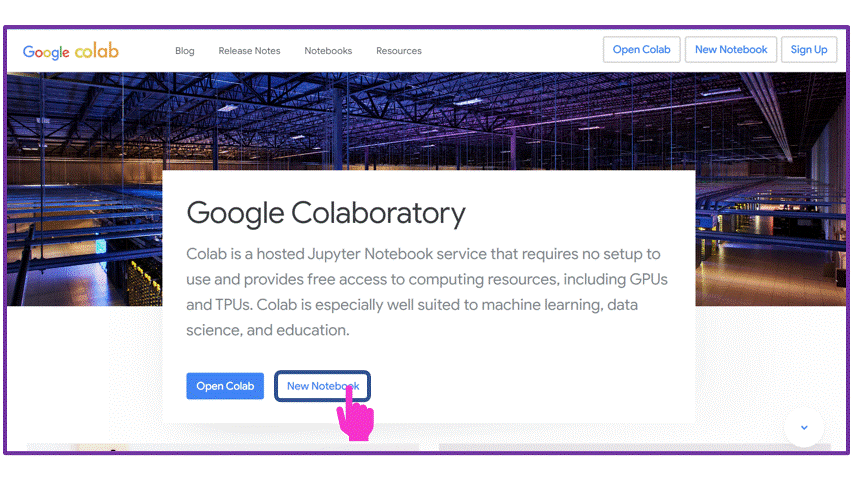
Open up a new notebook for this session: click “New Notebook”, then give the new file a sensible name. In a Python Notebook, you can create two different types of cells: a text cell, which can contain markdown-formatted text, and code cells, where you put Python code and can run it.
|
|---|
Hover the cursor over the bottom edge of the cell to show the options for a new text cell or code cell. Alt text: gif of Google Colab’s new notebook page, showing the new text cell and new code cell menu. |
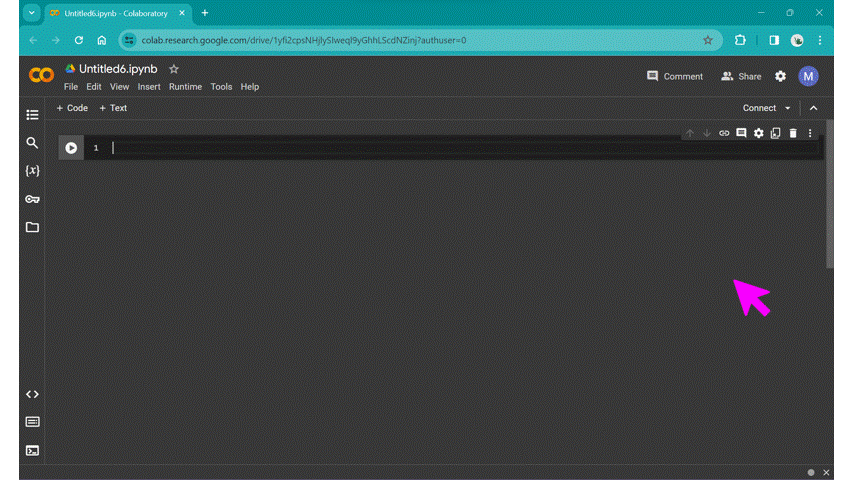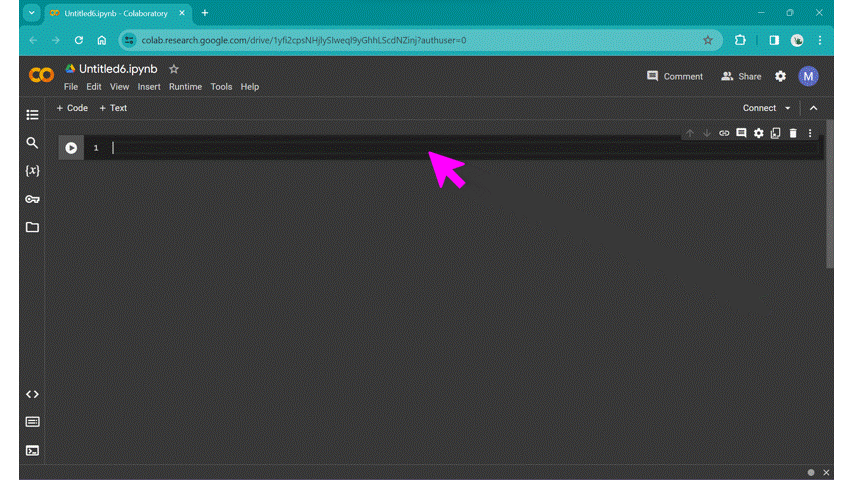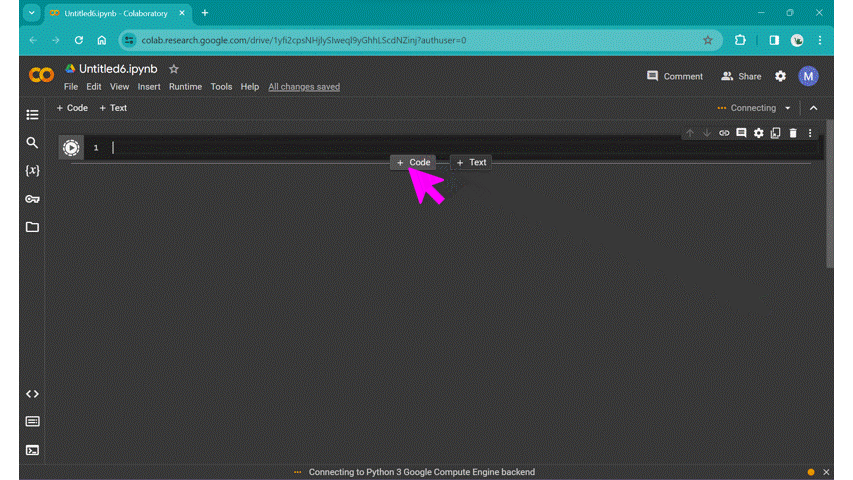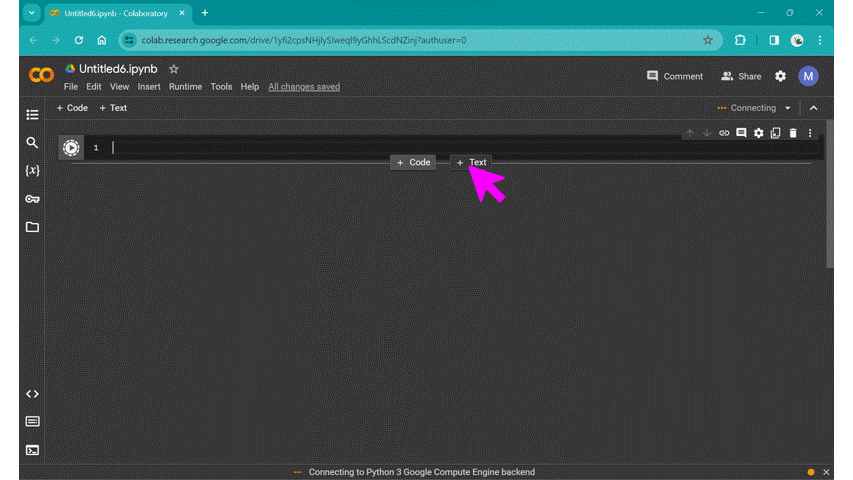
Try out the classic first program, “Hello World” from the first code cell, and click the run cell button to the left of the cell, or use the keyboard shortcut Ctrl + Enter:
The first cell may take a while to run as Colab connects to the runtime, but shortly it should output Hello World! below your first code cell.
Some useful keyboard shortcuts#
Action |
Shortcut |
|---|---|
Create new code cell |
Ctrl + M B |
Execute code cell |
Shift + Enter |
Refresher on the Python ecosystem#
One of the pre-requisites for this course is some basic Python experience, but don’t worry if you’ve forgotten how things work. For this course, we will be importing a variety of different libraries. It is a good practice to do this in the first cell of your notebook:
When we use a function from one of these libraries, we need to prefix it with the module name, for example matplotlib.pyplot.plot().
In this course, we will be using some common shortened names/aliases for libraries, that saves us typing out the full name every time we use them. You can replace the above code snippet with this:
The example matplotlib.pyplot.plot() above would now be instead written plt.plot().
Create some example data#
For this initial example, we are going to quickly generate some example data. Let’s assume we want to create a scatter plot with 50 pairs of (x, y) data. Let’s write some code that will generate 50 random numbers between zero and one.
Tip
You can add comments to your code using the \# symbol; this text is skipped over when you tell the code to run; it is just for you or anyone else who reads your code to better understand what you are doing.
Loading Data
Over the course of this material, we will run through how to load data from external files.
You can take a closer look at what this has produced by executing a cell that only contains x or y, or print(x), print(y) (what is the difference between x and print(x) in terms of output?).
Make a basic scatter plot#
Here’s a step-by-step run-through of how to build a basic scatter plot. A template is given at the end of these instructions.
How do I initialise a basic figure?#
So you have your data and you want to build a scatter plot to see if there’s any relationship between x and y.
To create a plot in Python, we will always follow a few key steps.
First, we initialise the figure and the axes. The fig object can be thought of as the page you draw your plot onto. The ax object is the box drawn by the x and y axes, the “panel” your plot will be drawn in.
The subplots function has the prefix plt because it’s from the matplotlib.pyplot library that we loaded early and assigned the shortened name plt.
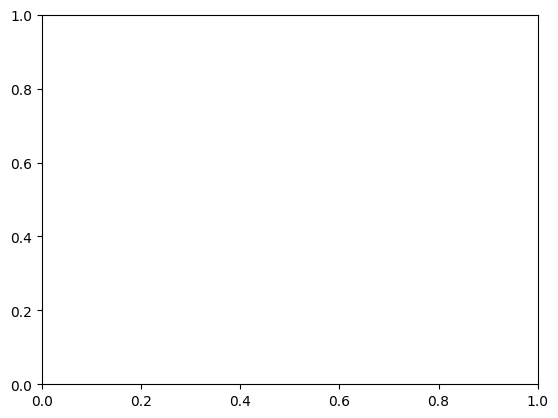
If you run this code, you should get an empty figure that looks something like this:
|
|---|
Empty axes without any data plotted. Alt text: white rectangle area surrounded by x and y axes, with labels from 0-1 on both. No data points are plotted. |
You can change the size of the fig object using the figsize argument; this takes inches by default.
How do I plot my data?#
In this example, we are creating a very simple scatter plot using the (x, y) pairs we created earlier. We can use the matplotlib scatter function to do this:
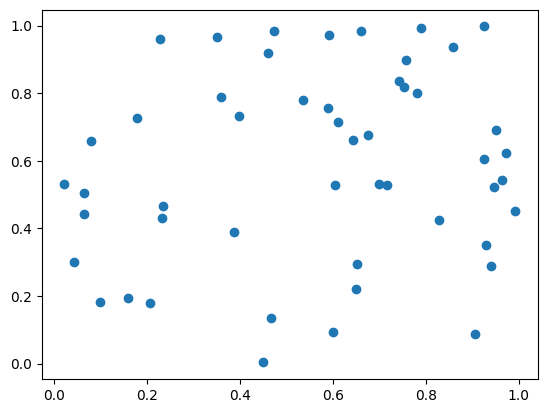
The prefix ax before .scatter tells this function that the scatter plot is to be drawn on the axes you set up earlier. We’ll later look at how this works for a multipart figure where you have a number of different panels/axes showing different things. This will produce a basic scatter plot using the default matplotlib aesthetic settings; it should look something like the figure below.
|
|---|
Basic scatterplot with no labels or title. Alt text: white rectangle area surrounded by x and y axes, with labels from 0-1 on both. Random data is plotted as large blue dots. |
But I’ve seen/used plt.scatter(x,y) before… what’s the difference?
In Matplotlib, there are two different approaches to making a plot. One is object oriented and the other is procedural… Essentially, these two terms are used to describe different programming languages and how they approach handling variables, data, and functions.
In general, Python is an object oriented programming language, which means it uses objects to get things done; in the code snippets above, the fig object is the box where everything relating to the plot goes, the ax object is a smaller box inside this that takes everything relating to that one panel of the plot. Because this is the approach taken in the Python language in general, this is the approach we will take as it helps to keep things consistent.
In contrast, the popular scientific programming language Matlab uses a procedural approach to plotting figures. Matplotlib was designed to emulate this, to allow users to swap to Python; this means you can also create plots without ever initialising a fig or ax object explicitly. This is an completely valid approach, but to avoid confusion we will be sticking to the object oriented way of plotting in this course.
Do not worry if this doesn’t make sense - the key take-away is that when searching through examples or reading other people’s code, you may see things done in a way that looks very similar, but uses subtly different function names - this is why!
If you’re interested and want to learn more, this is a good starting point.
How do I add labels?#
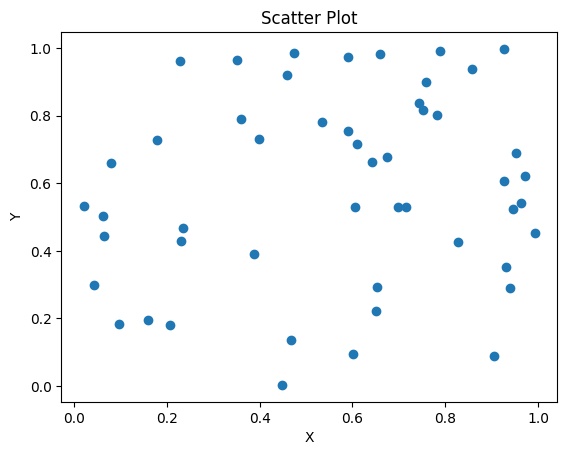
Plots like this do not convey the required information unless they have axes labels. Since this is not real data, we can just call the values on the x-axis “X” and the values on the y-axis “Y” - we don’t have any units to add.
|
|---|
Basic scatterplot with axes labels and a title. Alt text: a scatter plot of random data with both x and y in the range [0, 1]; data is represented by blue dots. The figure title reads “Scatter Plot”. |
You’ve just made your very first plot with Python!
How do I save this figure to my machine?#
There are a number of different ways to save a plot out of Google Colab.
|
|---|
Right click on the output figure to save it to your machine. Alt text: a screenshot of the context menu after right-clicking your output figure, including the option to “Save image as…” |
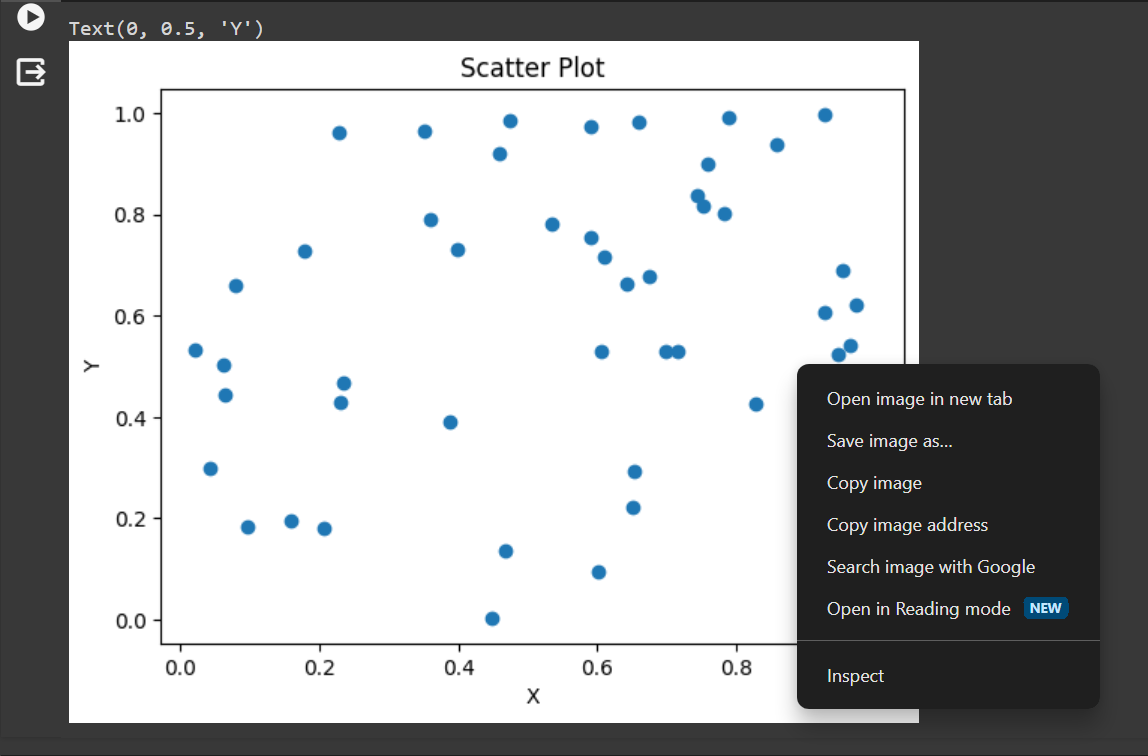
You can just right click/control-click the output image and either select “Save image as…” as shown in the above screenshot, or copy the output to a Powerpoint or similar. This option does not let you control resolution or image format.
Alternatively, you can use the savefig function to save the output:
If you add this to your code and run it, you can access the saved file from the files menu on the left of the screen (the folder symbol).
|
|---|
Use the files menu to access figures saved during the runtime. Alt text: a gif showing how to navigate to the saved file via the files menu on the left of the screen. |
Tip
Files saved here are only accessible while your virtual machine is up and running - once you close Colab, Google kills the machine you were using and everything you had saved is wiped. If you want your figure to survive, make sure to download them - or just accept that you need to replot them when you want them again!
What next#
You save your figure, but the resolution isn’t what you need - you want to use it in a presentation and when you add it to your slideshow, it looks pixelated and low-quality. How do we do this? Well, let’s have our first look at the official Matplotlib documentation!
Here’s the documentation for the savefig function. What can we learn from this?
We’re shown a little code-snippet called the call signature:
This essentially shows us all the possible options we can pass to the savefig function. These are called arguments. The first option, fname is what we passed before, when we entered "your_figure_name_goes_here.png". This is a required argument: the savefig function won’t work without it. All the other arguments are optional, and have defaults assigned with equals, for example dpi='figure'. This means that the dpi or dots-per-inch (a measure of resolution) is set to a default value for the figure (100 dpi by default in Matplotlib). If we scroll down past the call signature code snippet, we can see all the different arguments and a description for each. For dpi,
dpi : float or ‘figure’, default:
rcParams["savefig.dpi"](default:'figure') The resolution in dots per inch. If ‘figure’, use the figure’s dpi value.
This essentially tells you what we explain above, that the default value is set by the figure, which unless you have changed something, Matplotlib sets to 100 dpi (which you can find in the documentation for the figure object here). It also tells you that dpi can be set to a float value (such as 10.0, 300, 473.5 etc.) or to the default 'figure'. Assignment is done using an equals sign. Note, all optional arguments can be excluded from the function call:
Challenge
Change the dpi and size of your figure to allow it to be printed on a poster as a high-quality 10 inch \(\times\) 10 inch square. What dpi is recommended for printing? How do dpi and figure size interact?
Challenge
Save the figure in a vector format such as a .pdf or .svg instead of a .png. How might the dpi value work when saving a vector format image?
Scatter plot template#
This code snippet plots a scatter plot in a figure that’s 7 \(\times\) 4 inches, with a dpi of 300, in png format.
Dealing with overlap#
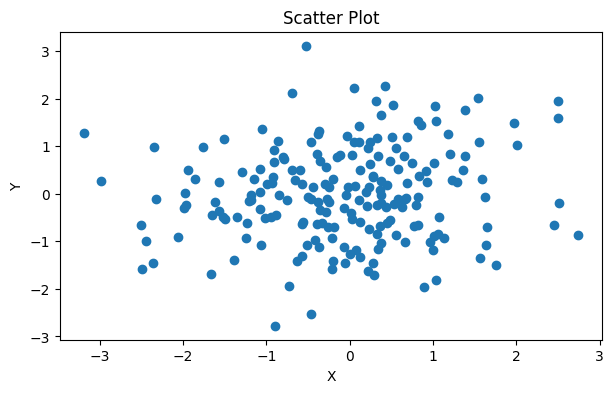
The examples above have very sparsely distributed data, but what about if you have data that overlaps?
|
|---|
Dense data can overlap, making it difficult to interpret. Alt text: a scatter plot with normally distributed data from -3 – 3 on both the x and y axis. |
Tip
You can generate random normally distributed data by using the np.random.normal() function
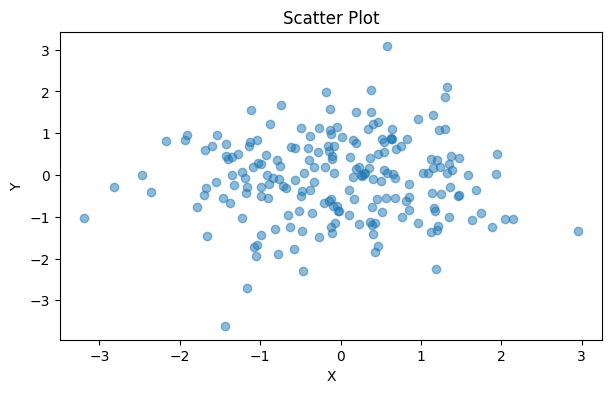
We can solve this by modifying the “alpha” or transparency of the points by replacing ax.scatter(x, y) with:
ax.scatter(x, y, alpha=0.5)
This allows you to more easily see where there are clusters of data:
|
|---|
Dense data can be plotted with lower opacity, allowing overlap to be better understood. Alt text: a scatter plot with normally distributed data from -3 – 3 on both the x and y axis. |
Visual encoding and additional variables#
So far, we have created a random data set and plotted it using the default settings provided by matplotlib: we have left the marker style, size and colour exactly as they are (apart from the brief discussion of overlapping data, above); each data point is identical.
This is sufficient if we only want to address the relationship between two variables x and y. But frequently, we will want to explore more than that.
Sophie Warnes provides us with a list of ways data can be encoded in her 2018 medium article “What’s visual ‘encoding’ in data viz, and why is it important?”:
Size
Shape
Colour
Grouping
Area
Position
Saturation
Line pattern
Line weight
Angle
Connections
Some of these (line weight, connections etc.) are more applicable to line plots, and will be covered in the next session, but properties such as the size, shape and colour of the markers can allow us to add another dimension to our scatter plot.
Unordered or categorical third dimension#
In the example code given, we defined x and y variables. What if these (x,y) pairs could be divided up into different groups or categories? Let’s assume for now, these different groups are stored separately:
Category |
Data |
|---|---|
Cat. 1 |
(x1, y1) |
Cat. 2 |
(x2, y2) |
Cat. 3 |
(x3, y3) |
x1 = np.random.rand(50)
y1 = np.random.rand(50)
x2 = np.random.rand(50)
y2 = np.random.rand(50)
x3 = np.random.rand(50)
y3 = np.random.rand(50)
We can use an almost-identical script to plot these results, just adding in additional lines of code for the new data series:
# Create a figure and axes, and set the figure size in inches
fig, ax = plt.subplots(figsize=(7, 4))
# Plot the data as a scatter plot
ax.scatter(x1, y1)
ax.scatter(x2, y2) # just repeat for the different data series
ax.scatter(x3, y3) # just repeat for the different data series
# Set title and labels
ax.set_title('Scatter Plot')
ax.set_xlabel('X')
ax.set_ylabel('Y')
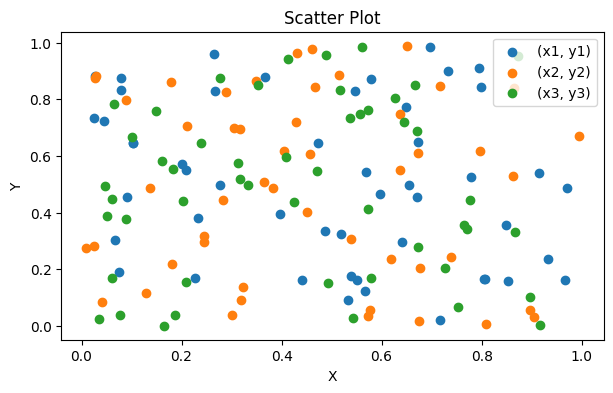
Because we now have an additional element aside from x,y position encoding our data, we need to include a legend. We must add labels to each of the data series:
ax.scatter(x1, y1, label="(x1, y1)")
ax.scatter(x2, y2, label="(x2, y2)")
ax.scatter(x3, y3, label="(x3, y3)")
Then we can add in a legend:
ax.legend()
|
|---|
Scatter plot with three separate categories. Matplotlib will cycle through a default colour palette for each new data series added. What’s an issue with this plot? (hint - look at the legend) |
Legend blocking some data?
Matplotlib attempts to draw the legend in an area where it’s overlapping the least amount of data, but sometimes there just isn’t room. We can move the legend off the plotting area by replacing the ax.legend() function call with this:
ax.legend(bbox_to_anchor=(0.5, 1.2), loc='upper center', ncol=3, frameon=False)
We will look at this in more detail in a later session.
Colour#
Matplotlib automatically assigns a different colour to the different data series, but this only one of the ways data can be encoded. The Seaborn documentation provides a really useful introduction to colour. We will delve into using colour more deeply over the next few sessions, but there are a few key points to note now:
Hue usually shouldn’t be the only way you visually encode data; it can be difficult to distinguish on some screens or when printed, might be illegible if printed in greyscale, and could be inaccessible to someone with a colour vision deficiency. In the session “Making comparisons: line plots” we will look more closely at colour choices.
Shape#
The shape of the marker can also be modified. Matplotlib allows a wide range of marker styles to be used. We will use these in the session “Making comparisons: line plots”.
Ordered third dimension#
In the example code given, we defined x and y variables. What if we also defined a z variable that is similar in structure to x and y (is an array of the same size, filled with similar random data)? We are going to explore the ways to display this third dimension in a 2D plotting.
We can define random x, y and z data. We’re going to use the randn function to get pseudo random normally distributed data:
# Define random x, y, z data
x = np.random.randn(200)
y = np.random.randn(200)
z = np.random.randn(200)
Colour#
Again, we can use colour to define the third dimension. In this case, because we want to show variation in z, which is a continuous variable and not categorical, we will use a colour map. The default colour map that matplotlib uses is called Viridis, and it’s a good choice for scientific visualisation - we will discuss why later!
# Create a figure and axes, and set the figure size in inches
fig, ax = plt.subplots(figsize=(7, 4))
# Plot the data as a scatter plot
ax.scatter(x, y, alpha=0.8, c=z) # alpha changes the opacity
# Set title and labels
ax.set_title('Scatter Plot')
ax.set_xlabel('X')
ax.set_ylabel('Y')
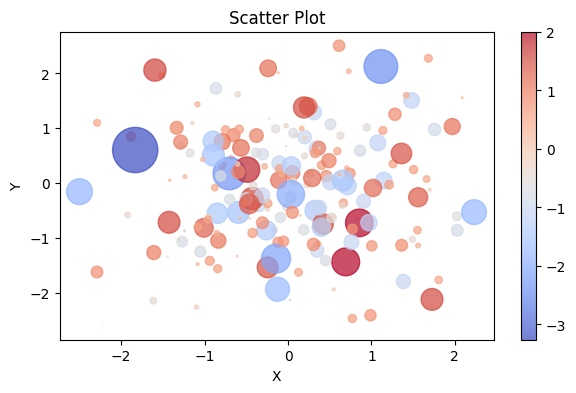
You can also use a diverging colour map, and make the markers a little bigger to make it more easily readable.
|
|---|
Caption Alt text: here |
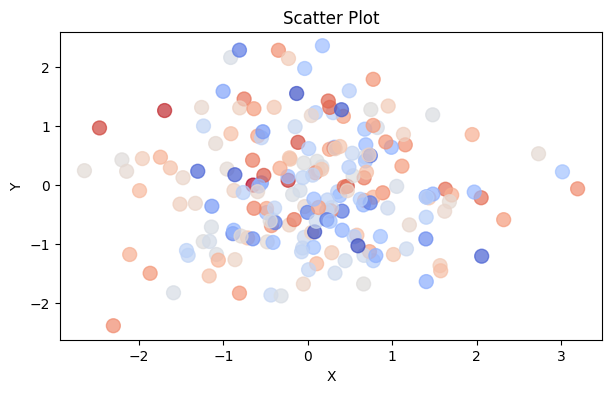
You can recreate this with the following code snippet:
# Plot the data as a scatter plot
ax.scatter(x, y, alpha=0.7, c=z, cmap="coolwarm", s=100)
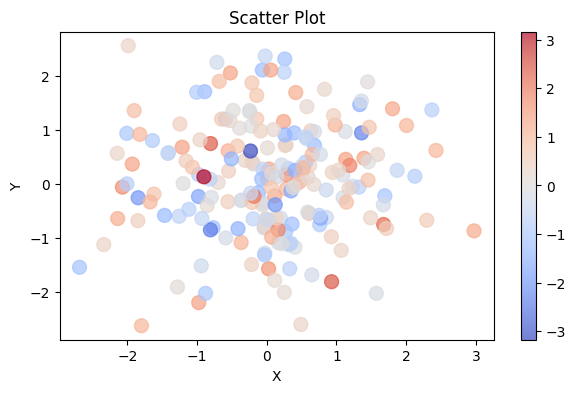
Of course, it’s important to include a colour scale so that people know what the colours represent:
# Plot the data as a scatter plot
a = ax.scatter(x, y, alpha=0.7, c=z, cmap="coolwarm", s=100)
fig.colorbar(a)
|
|---|
Caption Alt text: here |
Size#
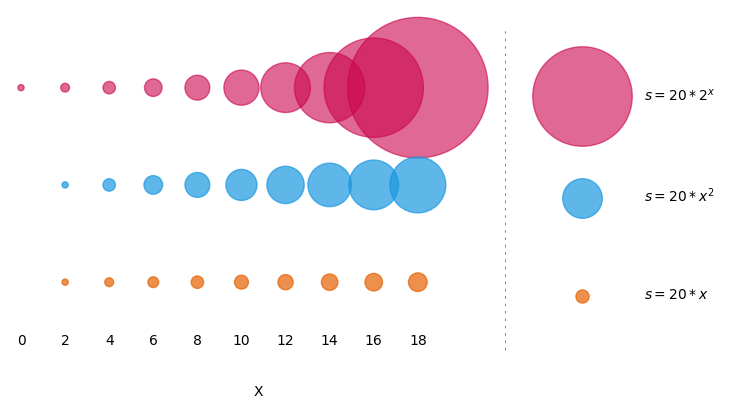
Another option for continuous data is to allow size to vary according to the third variable. As you can see from the example above, size can be set with the argument s=10. This value defines the area of the marker. In addition to defining the size of all the points with a scalar value, you can also pass in a variable or equation, for example the z variable, or sin(x), or 100*z**2. It’s important to know how the change in size be perceived by your audience before you use this.
|
|---|
Caption Alt text: here |
We can apply this to our scatter plot:
# Plot the data as a scatter plot
a = ax.scatter(x, y, alpha=0.7, c=z, cmap="coolwarm", s=100*z**2)
fig.colorbar(a)
|
|---|
Caption Alt text: here |